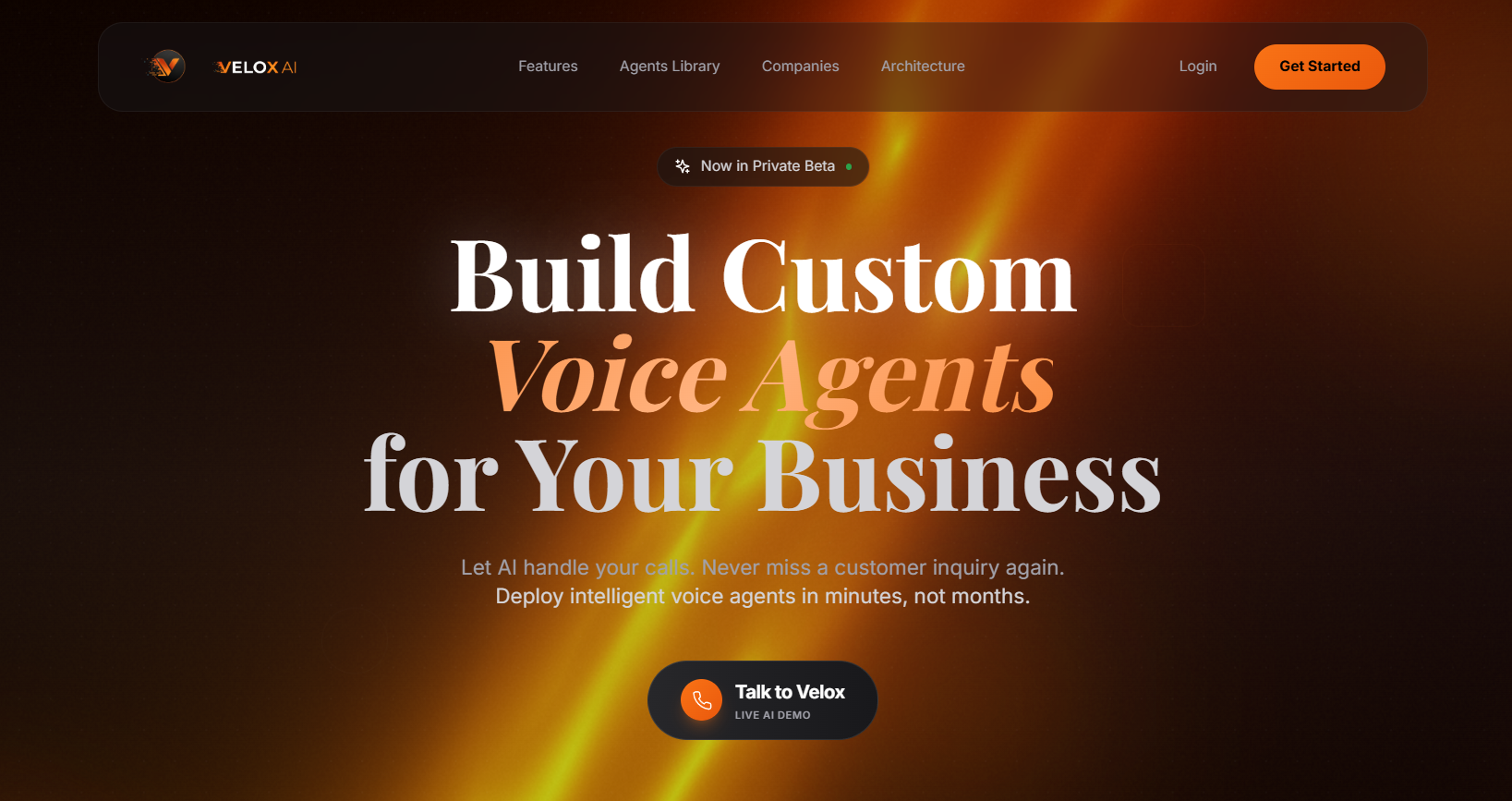
Velox AI
Velox AI is a B2B SaaS platform that lets businesses build, configure, and deploy their own real-time voice agents through a no-code dashboard. Sub-700 ms round-trip latency, full-duplex WebSocket streaming, semantic barge-in, and a provider-agnostic architecture that swaps STT, LLM, and TTS vendors at the agent level — including first-class support for 10 Indian languages.
Tech Stack
Project Overview
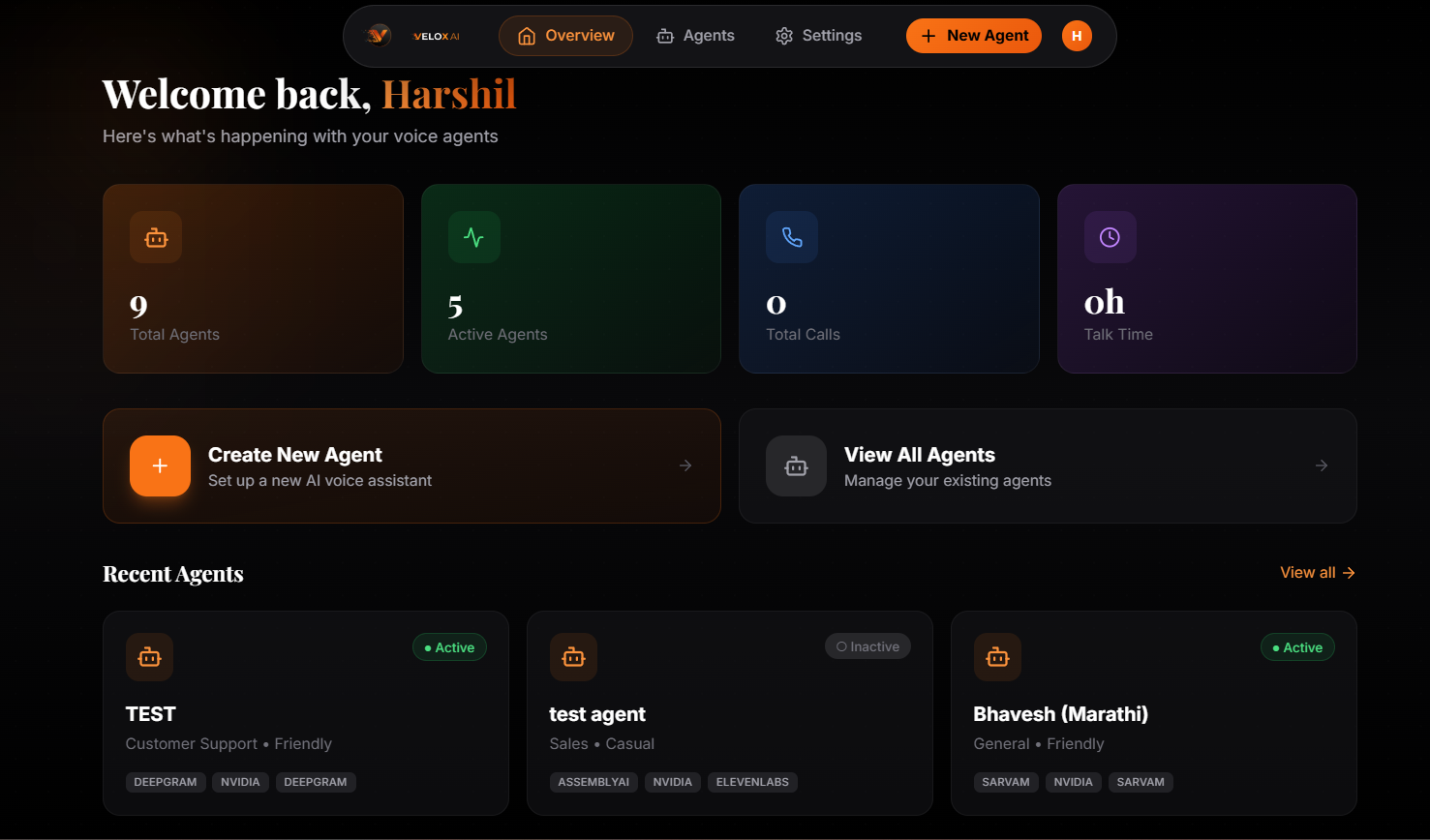
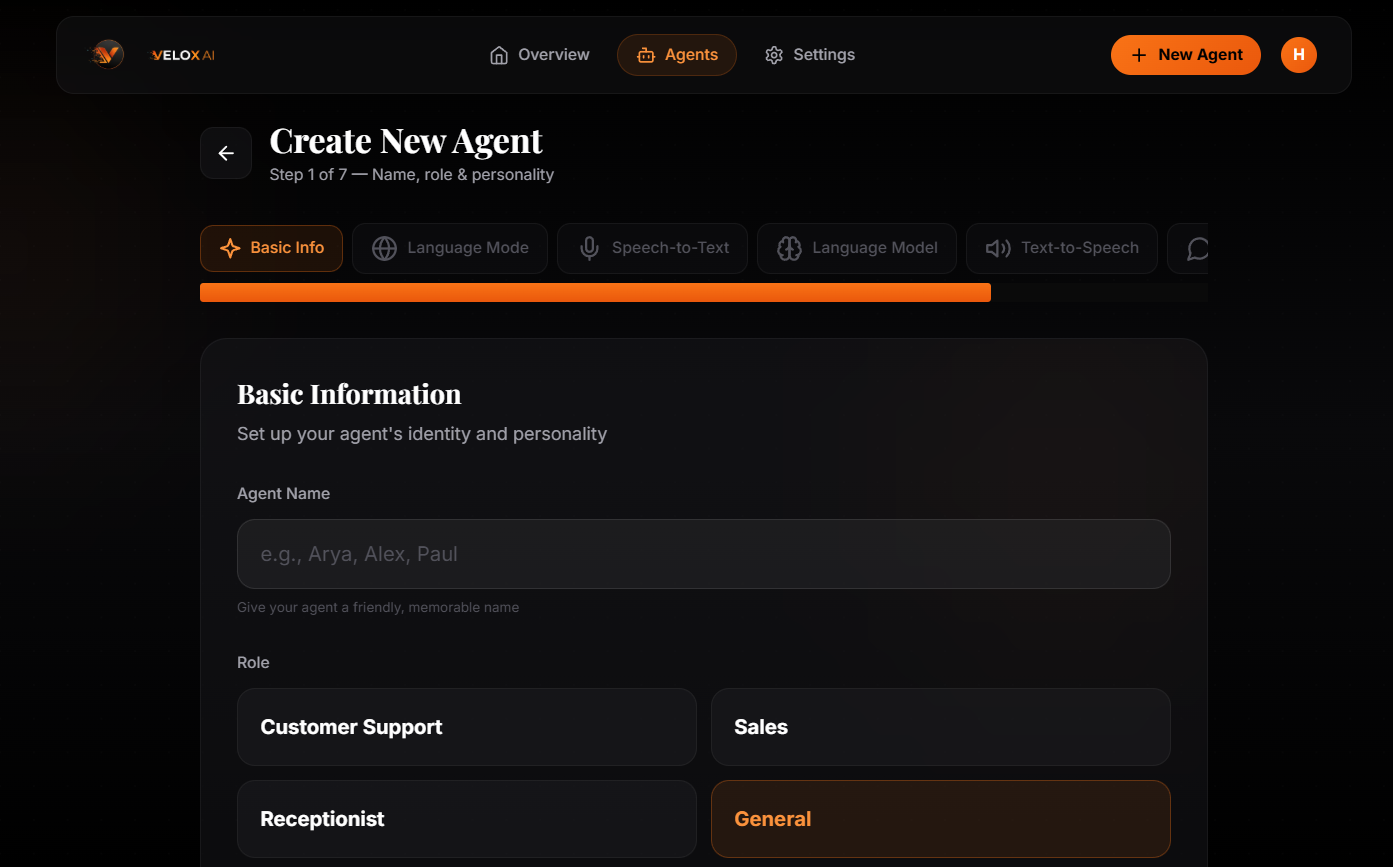
Velox AI is a B2B SaaS platform that lets businesses build, configure, and deploy their own real-time voice agents through a no-code dashboard. The product is positioned for SMB-segment teams — founders, operations leads, customer-experience managers — who own the outcome of phone interactions but don't write code. A 7-step Agent Builder wizard turns a few form fields into a working, deployable voice agent in under five minutes.
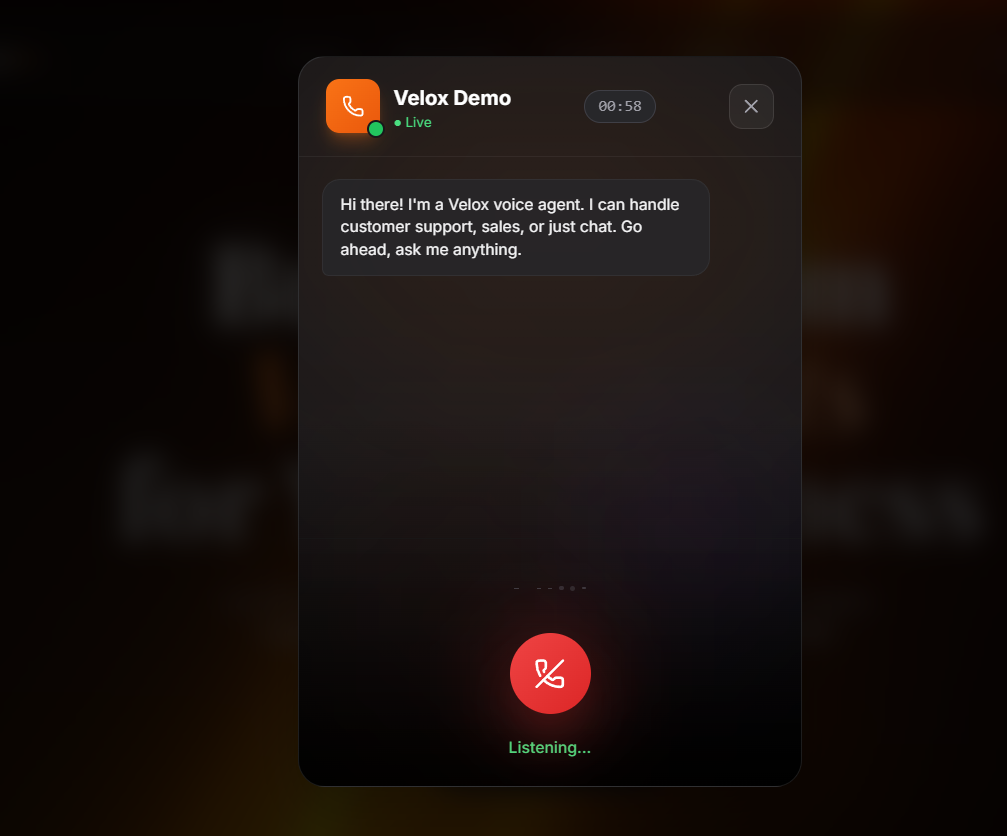
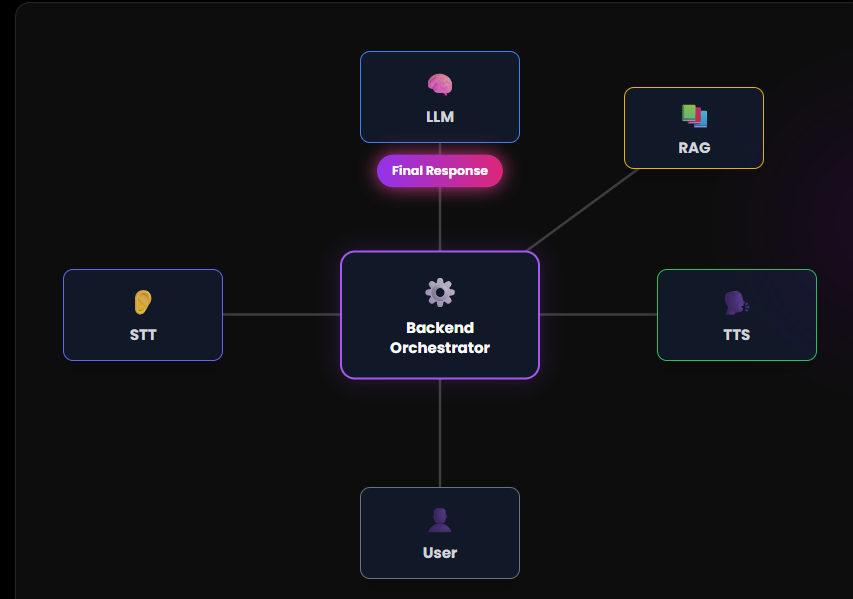
Under the hood, Velox is a streaming-first architecture. Audio flows through a four-task asyncio graph — STT loop, LLM stream, TTS worker, audio sender — that orchestrates partial transcripts, sentence-buffered TTS dispatch, and barge-in cancellation. The result is a sub-700 ms round-trip from "user stops speaking" to "user hears the agent," with full-duplex WebSocket streaming that supports interruption mid-sentence.
The defining architectural choice is a provider-agnostic adapter pattern: five STT providers (Deepgram, Sarvam, AssemblyAI, Gladia, Soniox), three LLM providers (Groq, Cerebras, NVIDIA NIM), and four TTS providers (Deepgram Aura, ElevenLabs, Sarvam, local Piper) all sit behind a single interface and are swappable per agent from the dashboard. This makes Indian-language voice agents a first-class citizen — full Hindi, Gujarati, Bengali, Marathi, Tamil, Telugu, Kannada, Malayalam, Odia and Punjabi support via Sarvam — while keeping the same English-grade engineering for every other language.
Each agent gets a private knowledge base. Users drag-and-drop PDFs, DOCX, TXT, or images (OCR'd server-side);
documents are parsed, chunked, embedded with a local SentenceTransformer model, and stored in a multi-tenant
Qdrant Cloud collection isolated by payload filter. At call time, the LLM decides when to invoke
search_knowledge_base as a function call, and a top-3 vector retrieval inlines the results back
into the conversation — with a filler phrase to mask the latency of the look-up.
For a much deeper technical breakdown — orchestrator code, sentence buffering, the barge-in cascade, the RAG pipeline, and where the 850 ms actually go — see the engineering blog: Technical Implementation of a Real-Time Voice Agent.

Let's Build Something Amazing Together
Impressed by what you see? Have a project idea in mind that needs someone with the right skills? I'm always looking for exciting new challenges and collaborations.